Core Concepts Overview¶
Kura is built on several key concepts that work together to analyze conversational data, enabling the discovery of meaningful patterns and insights from these interactions. This overview explains the major components and how they interact in the analysis pipeline.
Architecture¶
Kura's architecture consists of a pipeline of components that process conversational data through several stages:
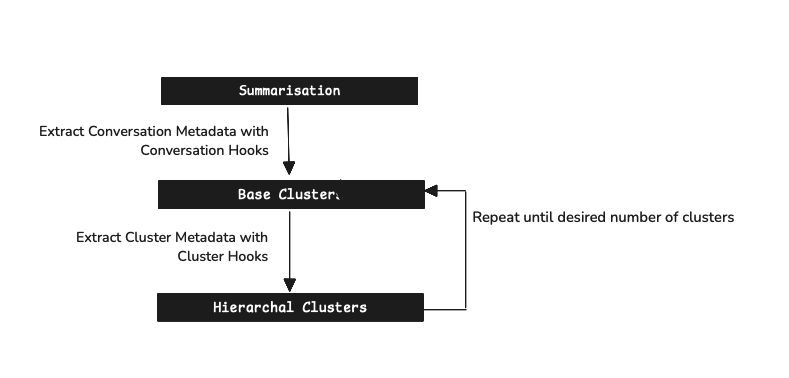
The main components are:
- Conversations: The raw chat data between users and assistants, serving as the foundational input.
- Summarization: Distilling lengthy conversations into concise task descriptions or core topics, which form the basis for subsequent analysis.
- Embedding: Representing these textual summaries as dense numerical vectors, capturing their semantic meaning for similarity measurement.
- Clustering: Grouping semantically similar summaries (via their embeddings) into 'base' clusters, identifying initial patterns in the data.
- Meta-Clustering: Organizing base clusters into a hierarchical structure, allowing for the exploration of insights at multiple levels of granularity, from broad themes to specific sub-topics.
- Dimensionality Reduction: Projecting high-dimensional embeddings into a lower-dimensional space (typically 2D or 3D) to enable visual exploration and pattern identification.
Processing Pipeline¶
When you run the kura pipeline, the data flows through the following steps:
- Load Conversations: Raw conversation data is loaded from your specified source.
- Generate Summaries: Each conversation is summarized, often into a concise task description or key topic. This summary becomes a primary unit for analysis.
- Extract Metadata: Optional metadata (e.g., conversation length, sentiment, user-defined tags, or other relevant attributes) is extracted from conversations. These attributes, sometimes referred to as 'facets', can provide additional dimensions for analysis, filtering, and deeper understanding of the clusters.
- Create Embeddings: The textual summaries are converted into vector representations (embeddings) that capture their semantic content.
- Perform Base Clustering: Embeddings are used to group semantically similar summaries into initial 'base' clusters, forming the first layer of identified patterns.
- Apply Meta-Clustering: Base clusters are iteratively combined or organized into a hierarchical structure. This allows for navigation and exploration of insights from broad, overarching themes down to more specific, granular patterns.
- Reduce Dimensions: High-dimensional embeddings (and their cluster assignments) are projected, typically into a 2D or 3D space. This facilitates visual exploration, helping to understand the relationships between clusters and identify outliers or emergent patterns.
- Save Checkpoints: Results from each significant step are saved as checkpoint files, enabling efficient resumption and review of the analysis process.
Key Classes¶
Kura is designed with a modular architecture, allowing components to be customized or replaced:
Main Orchestrator¶
Kura(kura.py): The main class that coordinates the entire pipeline and manages checkpoints
Component Classes¶
BaseEmbeddingModel/OpenAIEmbeddingModel(embedding.py): Convert text to vector representationsBaseSummaryModel/SummaryModel(summarisation.py): Generate summaries from conversationsBaseClusterModel/ClusterModel(cluster.py): Group similar summaries into clustersBaseMetaClusterModel/MetaClusterModel(meta_cluster.py): Create hierarchical cluster structuresBaseDimensionalityReduction/HDBUMAP(dimensionality.py): Project embeddings to 2D space
Data Models¶
Conversation(types/conversation.py): Represents a chat conversation with messagesConversationSummary(types/summarisation.py): Contains a summarized conversationCluster(types/cluster.py): Represents a group of similar conversationsProjectedCluster(types/dimensionality.py): Represents clusters with 2D coordinates
Extensibility¶
Each component has a base class that defines the required interface, allowing you to create custom implementations:
# Example of creating a custom embedding model
from kura.base_classes import BaseEmbeddingModel
class MyCustomEmbeddingModel(BaseEmbeddingModel):
async def embed(self, texts: list[str]) -> list[list[float]]:
# Your custom embedding logic here
...
Checkpoints¶
Kura saves intermediate results to checkpoint files, allowing you to:
- Resume processing after interruptions
- Inspect intermediary results
- Share analysis results with others
- Visualize results without reprocessing
Next Steps¶
To understand each component in more detail, explore the following pages: