Kura: Procedural API for Chat Data Analysis¶


![]()


Your AI assistant handles thousands of conversations daily. But do you know what users actually need?
Kura is an open-source library for understanding chat data through machine learning, inspired by Anthropic's CLIO. It automatically clusters conversations to reveal patterns, pain points, and opportunities hidden in your data.
The Hidden Cost of Not Understanding Your Users¶
Every day, your AI assistant or chatbot has thousands of conversations. Within this data lies critical intelligence:
- 80% of support tickets stem from 5 unclear features
- Feature requests repeated by hundreds of users differently
- Revenue opportunities from unmet needs
- Critical failures affecting user trust
Make sense of that data with Kura today
What Kura Does¶
Kura transforms chaos into clarity
Imagine having 10,000 scattered conversations and ending up with 20 crystal-clear patterns that tell you exactly what your users need. That's what Kura does.
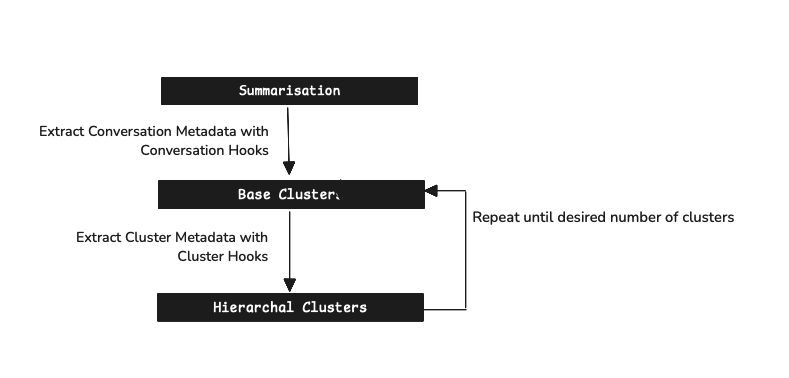
Kura is built for scale and flexibility, processing your conversation data through a sophisticated four-stage pipeline.
- Smart caching makes re-runs 85x faster
- Checkpointing system never loses progress
- Parallel processing handles thousands of conversations,
- Extensible design works with any model (OpenAI, Anthropic, local)
We also provide a web-ui that ships with the package to visualise the different clusters that we've extracted.
Summarization¶
Extract core intent from each conversation. Works with any conversation length - from quick questions to complex multi-turn dialogues. Uses AI to distill the essence while preserving critical context and user intent.
Transforms: "I've been trying to cancel my subscription for 30 minutes and the button doesn't work and I'm really frustrated..." → "Cancel subscription"
Semantic Clustering¶
Group by meaning, not keywords. The AI understands synonyms, context, and user intent across different phrasings and languages.
Transforms: "cancel subscription", "stop my account", "end my service", "how do I delete my profile?", "terminate my membership" → Single cluster: "Account Cancellation"
Meta-Clustering¶
Build hierarchy of insights. Creates multiple levels of organization: individual issues → feature categories → business themes.
Transforms: "Account Cancellation", "Login Problems", "Password Resets" → "Account Management Issues" (40% of support load)
Dimensionality Reduction¶
Create interactive exploration maps. See clusters as bubbles on a 2D map where proximity indicates similarity. Discover edge cases, identify emerging trends, and spot conversations that don't fit existing patterns.
Transforms: High-dimensional cluster embeddings → Interactive 2D visualization map
The result? Instead of drowning in individual conversations, you get a clear picture of what's actually happening across your entire user base.
📚 Documentation¶
-
Get Started Fast
Install Kura and configure your first analysis pipeline in minutes.
-
Quick Start
Jump right in with a complete example that processes conversations from raw data to insights.
-
: Complete Workflow
See how a full analysis looks from loading data to interpreting clusters and extracting actionable insights.
-
Core Concepts
Learn how Kura works under the hood - from conversation loading and embedding to clustering and visualization.
New to Kura?
Start with the Installation Guide → Quick Start → Core Concepts for the best learning experience.
Quick Start¶
import asyncio
from kura.summarisation import SummaryModel, summarise_conversations
from kura.cluster import (
ClusterDescriptionModel,
generate_base_clusters_from_conversation_summaries,
)
from kura.meta_cluster import MetaClusterModel, reduce_clusters_from_base_clusters
from kura.dimensionality import HDBUMAP, reduce_dimensionality_from_clusters
from kura.checkpoints import JSONLCheckpointManager
from kura.types import Conversation, ProjectedCluster
from kura.visualization import visualise_pipeline_results
# Load conversations
conversations = Conversation.from_hf_dataset(
"ivanleomk/synthetic-gemini-conversations", split="train"
)
# Set up models with new caching support!
from kura.cache import DiskCacheStrategy
summary_model = SummaryModel(cache=DiskCacheStrategy(cache_dir="./.summary_cache"))
cluster_model = ClusterDescriptionModel()
meta_cluster_model = MetaClusterModel(max_clusters=10)
dimensionality_model = HDBUMAP()
# Set up checkpoint manager
checkpoint_mgr = JSONLCheckpointManager("./checkpoints", enabled=False)
# Run pipeline with explicit steps
async def process_conversations() -> list[ProjectedCluster]:
# Step 1: Generate summaries
summaries = await summarise_conversations(
conversations, model=summary_model, checkpoint_manager=checkpoint_mgr
)
# Step 2: Create base clusters
clusters = await generate_base_clusters_from_conversation_summaries(
summaries, model=cluster_model, checkpoint_manager=checkpoint_mgr
)
# Step 3: Build hierarchy
meta_clusters = await reduce_clusters_from_base_clusters(
clusters, model=meta_cluster_model, checkpoint_manager=checkpoint_mgr
)
# Step 4: Project to 2D
projected = await reduce_dimensionality_from_clusters(
meta_clusters, model=dimensionality_model, checkpoint_manager=checkpoint_mgr
)
return projected
# Execute the pipeline
results = asyncio.run(process_conversations())
visualise_pipeline_results(results, style="enhanced")
This in turn results in the following output
Programming Assistance Clusters (190 conversations)
├── Data Analysis & Visualization (38 conversations)
│ ├── "Help me create R plots for statistical analysis"
│ ├── "Debug my Tableau dashboard performance issues"
│ └── "Convert Excel formulas to pandas operations"
├── Web Development (45 conversations)
│ ├── "Fix React component re-rendering issues"
│ ├── "Integrate Stripe API with Next.js"
│ └── "Make my CSS grid responsive on mobile"
└── ... (more clusters)
Performance: 21.9s first run → 2.1s with cache (10x faster!)
Frequently Asked Questions¶
-
Can Kura work with my data and models? Yes! Kura supports any conversation format (JSON, CSV, databases) and works with OpenAI, Anthropic, local models, or custom implementations.
-
How much data do I need? Start with 100+ conversations for basic patterns, 1,000+ for robust clustering, or 10,000+ for detailed insights.
-
Is my data secure? Absolutely. Run Kura entirely on your infrastructure, use local models for complete isolation, and analyze patterns without exposing individual conversations.
-
What languages does Kura support? Any language supported by your chosen model - from English to 90+ languages with models like GPT-4.
-
Can I integrate Kura into my application? Yes, Kura is designed as a library for seamless integration into your existing async applications.
About¶
Kura is under active development. If you face any issues or have suggestions, please feel free to open an issue or a PR. For more details on the technical implementation, check out this walkthrough of the code.